The Truth About Enterprise RAG: Why 80% of AI Engineering is Data Orchestration
Building a RAG pipeline in a 10-minute tutorial is fun. You take a perfectly clean PDF, generate some embeddings, toss them into a Vector DB, and call it a day. The LLM responds beautifully, and you feel like an AI wizard.
Building one for a highly regulated enterprise? That's a whole different beast.
I've been spending my days building Agentic AI systems for a large enterprise. If you watch the online courses, the process looks beautiful. Then you step into the real world...
The Reality Check
Enterprise data is wild. It's locked in silos. Formats are all over the place. Tables overlap, and you're dealing with legacy reports that have absolutely zero structure.
If you feed this messy data straight into an LLM, I don't care how smart your multi-agent setup is — it's going to hallucinate with 100% confidence.
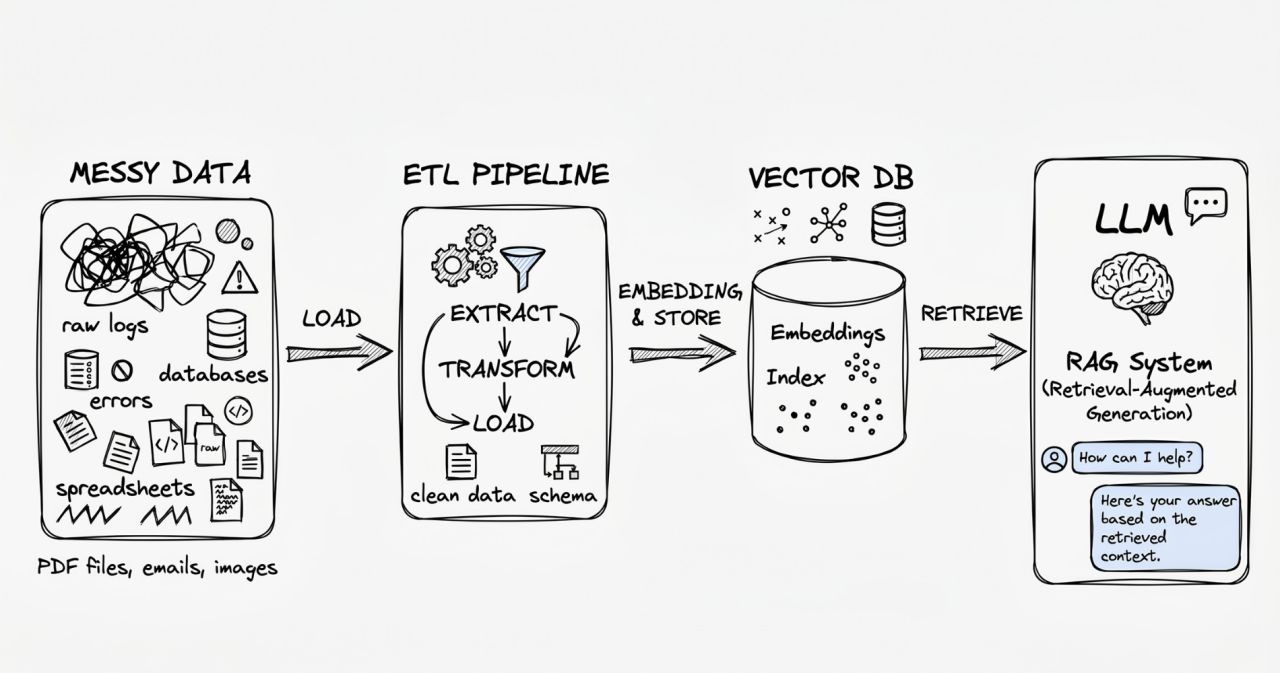
Figure 1: Enterprise RAG Pipeline — notice the heavy lifting happens before the LLM ever sees the data
The Uncomfortable Truth
Looking back at my recent engineering notes, the truth is pretty clear: 80% of an AI Software Engineer's job isn't writing the perfect prompt. It's data orchestration.
We spend weeks arguing about:
- Which embedding model is best
- Whether to use ReAct or Plan-and-Solve agents
- What temperature setting produces better reasoning
But the real bottleneck? The garbage data pipeline feeding your pristine vector store.
The Real Heavy Lifting
Here's where the actual work happens:
1. Building ETL Pipelines That Don't Break
Your tutorial uses a neat API endpoint. Enterprise reality? You're pulling from:
- Legacy SQL databases from 2008
- Shared drives with 10 years of accumulated PDFs
- Third-party systems with rate limits and ancient authentication
- Excel sheets that 3 different departments have been editing independently
# What tutorials show you
documents = load_pdf("clean_document.pdf")
# What enterprise actually looks like
def extract_enterprise_document(file_path):
if file_path.endswith('.pdf'):
if is_scanned_pdf(file_path):
return ocr_with_fallback(file_path)
elif has_complex_tables(file_path):
return extract_tables_separately(file_path)
else:
return extract_text_with_layout(file_path)
elif file_path.endswith('.xlsx'):
return normalize_merged_sheets(file_path)
elif file_path.endswith('.docx'):
return handle_tracked_changes(file_path)
# ... 47 more edge cases
2. Chunking Strategies That Keep Context Intact
Fixed-size chunking? Good luck. When your document has:
- Multi-level headers
- Cross-references to other sections
- Tables that span multiple pages
- Footnotes that are critical to understanding
You need semantic chunking that respects document structure:
# Semantic chunking by section boundaries
chunks = semantic_split(
documents,
separators=['\n\n', '\n'],
keep_separator=True,
chunk_size=1000,
chunk_overlap=200
)
# Then add metadata for retrieval
for chunk in chunks:
chunk.metadata['section_hierarchy'] = extract_hierarchy(chunk)
chunk.metadata['document_type'] = classify_document(chunk)
chunk.metadata['has_references'] = detect_cross_references(chunk)
3. Scrubbing Noise Before It Reaches Your Vector Space
Your embedding model doesn't know the difference between:
- Actual content
- Page headers/footers
- Watermarks
- Disclaimers
- Redacted text markers
All of it becomes vectors. All of it gets retrieved. All of it confuses your LLM.
Garbage in, gospel out.
What Actually Matters
GenAI gets all the spotlight right now, but solid data engineering is the quiet MVP. Your AI is really only as smart as the data pipeline feeding it.
The teams winning at enterprise AI aren't the ones with the fanciest prompts. They're the ones who:
- Built robust document parsers for their specific domain
- Implemented quality gates at every pipeline stage
- Monitor retrieval quality, not just LLM outputs
- Have feedback loops from production back to data cleaning
For Anyone Building AI in Production
What's the most cursed data format you've had to clean up for a RAG system?
I've seen:
- Scanned faxes from the 1990s (yes, really)
- Excel sheets where merged cells encode critical business logic
- PDFs where the "text" is actually embedded images with no OCR
- Database exports with 47 different date formats in the same column
Your AI is only as smart as your data pipeline.
Want to discuss enterprise AI challenges? Find me on LinkedIn or check out my other work.